Je to ovocie alebo zelenina? Nad touto otázkou si lámali hlavu celé generácie najlepších mozgov z celého sveta. Vedenie Technickej univerzity si v nasledovnej päťročnici naplánovalo vyskúmať konečnú odpoveď na problém klasifikácie tovaru v oddelení Ovocia a zeleniny v sklade Študentských domovoch a jedální. Nový spôsob rozdelenia tovaru bude vyskúšaný v novom bufete "Aninelez" (pravdepodobne v budove TaHni-Com).
Pomôžte pracovníkom v školskom bufete. Pri identifikácii tovaru pomôže pracovníkom bufetu Váš automatický dialógový systém, a.k.a chatbot. Je dôležité, aby výsledok bol čo najlepší, pretože konkurzu na túto pozíciu v novom bufete sa môžete zúčastniť aj VY!
Naučíte sa:
- Práca s jednoduchým znalostným systémom.
- Práca s nevyváženým vyhľadávacím stromom.
- Prechádzanie binárneho stromu spôsobom preorder a postorder.
Budete potrebovať ovládať základy spojkových zoznamov. Inak nebudete potrebovať žiadne špeciálne knižnice, len štandardné na:
- prácu s reťazcami,
- prácu so vstupom a výstupom,
- prácu s pamäťou.
Úloha
Vašou úlohou bude naprogramovať chatbota, ktorý pomôže budúcim zamestnancom bufetu pri rozlišovaní druhov tovaru pomocou série otázok. Báza znalostí sa skladá z otázok typu áno a nie a odpovedí.
Systém najprv načíta bázu otázok a odpovedí. Každá otázka alebo odpoveď sa nachádza na práve jednom riadku. Odpovede sú vyznačené hviezdičkou na začiatku riadka. Po otázke na najprv nasleduje načítanie ďalšieho kroku áno a potom kroku nie. Každý krok znalostného systému je alebo odpoveď alebo ďalšia otázka. Báza pravidiel je ukončená prázdnym riadkom.
Otázky a odpovede spolu tvoria binárny vyhľadávací strom zapísaný vo formáte pre-order.
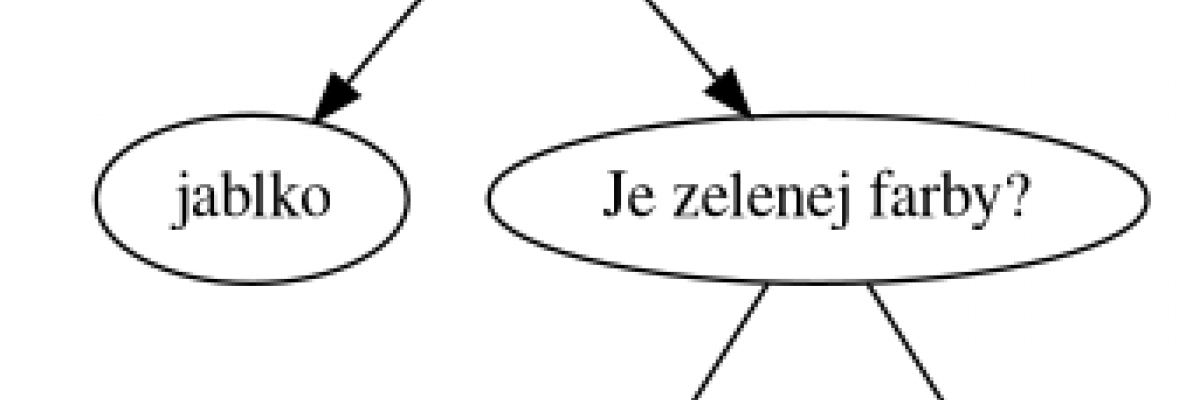
Príklad bázy pravidiel s dvoma otázkami a troma druhmi tovaru:
Je to ovocie alebo zelenina ?
* Jablko
Je to zelenej farby ?
* Kaleráb
* MrkvaPo načítaní bázy pravidiel vypíšte počet tovarov v báze pravidiel. V prípade, že sa nedá správne načítať báza pravidiel vypíšte chybové hlásenie. Báza pravidiel je od používateľského vstupu oddelená prázdnym riadkom.
Ak sa bázu pravidiel podarilo načítať, spustite znalostný systém prvou otázkou. Spustenie znalostného systému znamená jeho rekurzívne prechádzanie typu preorder od koreňového uzla. Pri prechádzaní najprv zobrazte otázku alebo odpoveď ktorá sa nachádza v aktuálnom uzle. Ďalšie otázky alebo odpovede zobrazujte podľa toho, či používateľ odpovedá a pre prvú
možnosť alebo n pre druhú. Ak systém nájde odpoveď, vypíšte správu a skončite program. Ak používateľ zadá nesprávny vstup, vypíšte správu a skončite program.
Príklad vstupu:
Je to ovocie alebo zelenina (a/n) ?
* Jablko
* Mrkva
nPríklad výstupu:
MUDrC to vie.
Pozna 2 druhov ovocia a zeleniny.
Odpovedajte 'a' alebo 'n'
Je to ovocie alebo zelenina (a/n) ?
* Mrkva
KoniecZopakujte si
Uistite sa, že rozumiete týmto pojmom:
- Binárny strom
- inorder, preorder, postorder prechádzanie stromu (binary tree traversal).
- Rozhodovací strom
Ako na to
Na návrh a implementáciu znalostného systému, ktorý bude vedieť odpovedať na otázky typu áno a nie je vhodný binárny vyhľadávací stom. Na uloženie jednej položky databázy budete potrebovať tieto položky:
- Znenie otázky alebo odpovede
- Smerník na odpoveď áno
- Smerník na odpoveď nie
V prípade, že sú smerníky na áno a nie nulové, uzol je listový a naznačuje konečnú odpoveď znalostného systému.
1. Načítanie bázy pravidiel zo súboru do binárneho stromu
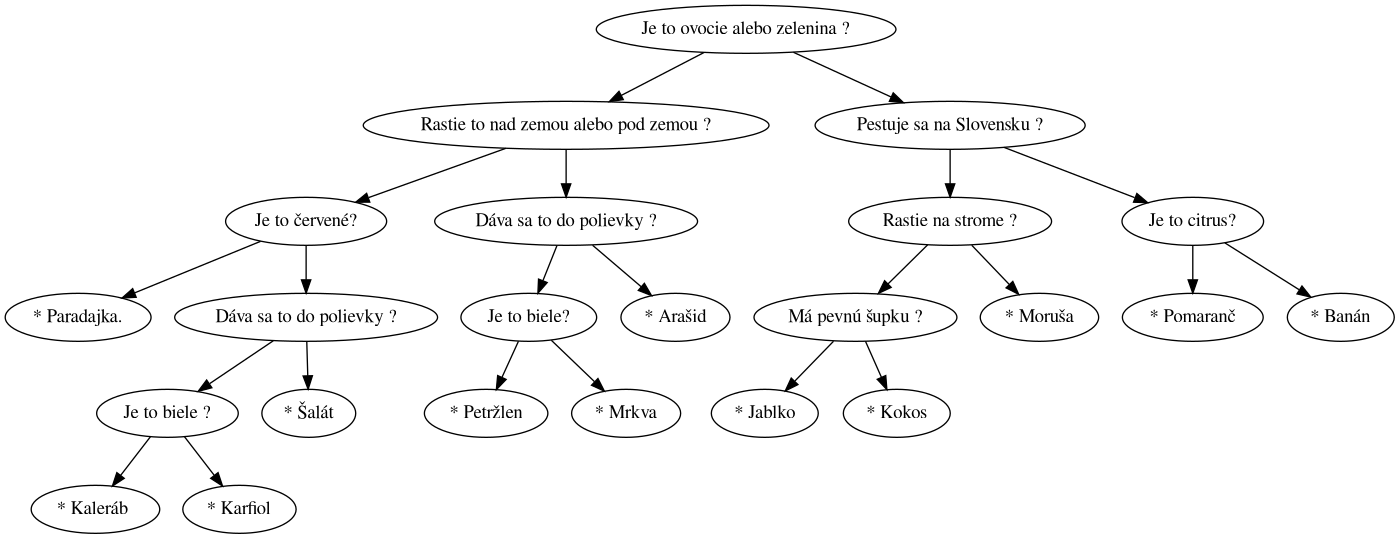
Vzorovú znalostnú databázu vieme zapísať do textového súboru takto:
Je to ovocie alebo zelenina ?
Rastie to nad zemou alebo pod zemou ?
Je to červené?
* Paradajka.
Dáva sa to do polievky ?
Je to biele ?
* Kaleráb
* Karfiol
* Šalát
Dáva sa to do polievky ?
Je to biele?
* Petržlen
* Mrkva
* Arašid
Pestuje sa na Slovensku ?
Rastie na strome ?
Má pevnú šupku ?
* Jablko
* Kokos
* Moruša
Je to citrus?
* Pomaranč
* BanánPri načítavaní postupujeme metódou preorder:
- Najprv načítame hodnotu. (Názov otázky alebo ovocia). Prípade, že sa názov začína na '*', tak je uzol listový a potomkov ďalej nemusíme načítavať.
- Potom načítame ľavý uzol, ktorý zodpovedá prvej odpovedi.
- Potom potom načítame pravý uzol (druhá odpoveď).
Výsledný binárny strom pre vzorovú databázu bude vyzerať takto:
Najprv si vytvorte funkciu, ktorá načíta bázu pravidiel s jednou otázkou.
struct tree* read_tree(){
char buffer[SIZE];
memset(buffer,0,SIZE);
char* r = fgets(buffer,SIZE,stdin);
assert(r);
struct tree* node = calloc(1,sizeof(struct tree));
memcpy(node->value,buffer,SIZE);
return node;
}Nezabudnite dynamicky alokovanú pamäť uvoľniť:
void destroy_tree(struct tree* tree){
free(tree);
}Ďalej si skúste funkciu pre vytvorenie stromu zovšeobecniť tak, aby načítala ľubovoľnú databázu. Môžete to navrhnúť ako rekurzívnu funkciu. Využijeme fakt, že načítať jeden riadok už vieme. Načítavať sa bude podľa pravidiel preorder, teda najprv ide otázka, potom odpoveď áno a potom nie. Ak sa riadok začíta symbolom *, nebude potrebné načítať ďalšie otázky na nižšej úrovni. V prípade, že sa riadok nezačína symbolom *, rekurzívne načíta ľavého a pravého syna, ktoré sa nachádzajú na ďalších riadkoch. Ľavý syn bude obsahovať, to čo sa má diať po odpovedi "áno", pravý syn bude obsahovať to, čo sa bude diať po odpovedi "nie".
struct tree* read_tree(){
char buffer[SIZE];
memset(buffer,0,SIZE);
char* r = fgets(buffer,SIZE,stdin);
assert(r);
struct tree* node = calloc(1,sizeof(struct tree));
memcpy(node->value,buffer,SIZE);
// Ak je nacitany riadok listovy uzol ,tak netreba robit nic
// inak rekurzivne nacitanie laveho syna
// a rekurzivne nacitanie praveho syna
return node;
}Báza pravidiel je od používateľského vstupu oddelená prázdnym riadkom. Po načítaní stromu a pred začiatkom spracovania vstupu od používateľa je potrebné overiť, či sa tam ten prázdny riadok nachádza. Ak nie, tak niečo nie je v poriadku.
Upravte aj funkciu pre uvoľnenie pamäte tak aby uvoľnila celý binárny strom. Inšpirujte sa funkciou pre uvoľnenie spojkového zoznamu.
Pri ladení môžte využiť aj rekurzívnu funkciu pre vizualizáciu binárneho stromu. Táto funkcia zároveň demonštruje preorder prechádzanie binárneho stromu ktoré využijete pri načítaní. Najprv sa vypíše otázka alebo odpoveď a ak existujú podstromy, tak výpis rekurzívne pokračuje na ľavý a pravý podstrom.
Táto funkcia vypíše každú úroveň stromu s väčším odsadením. Výpis stromu v textovom formáte:
void print_tree(struct tree* tree,int offset){
for (int i = 0; i < offset; i++){
printf(" ");
}
printf("%s",tree->question);
if (tree->left){
print_tree(tree->left,offset +3);
print_tree(tree->right,offset +3);
}
}Ak máte na nainštalovaný balíček GraphViz, môžete si vytvoriť aj pekný obrázok stromu. Ak program na štandardný výstup vygeneruje zápis grafu v jazylu dot, potom obrázok dostaneme:
program | dot -T png -o obrazok.pngPodmienkou je ale aby každý uzol mal svoj unikátny identifikátor id. Ten pridáme počas načítania stromu podľa počítadla.
Aby sme pri rekurzívnej funkcii mohli používať počítadlo bez globálnej premennej musíme použiť smerníkovú premennú:
struct tree* read_tree(int* counter)Funkcie pre výpis stromu vo formáte dot:
// Výpis stromu vo formáte Graphviz bez hlavičky
void print_dot_node(struct tree* node){
if (node == NULL){
return;
}
print_dot_node(node->left);
// Parameter ID je cislo uzla. Cislo uzla urcite pri nacitani pomocou pocitadla.
printf("%d [label=\"%s\"];\n",node->id, node->question);
if (node->left){
printf("%d -> %d;\n",node->id,node->left->id);
}
if (node->right){
printf("%d -> %d;\n",node->id,node->right->id);
}
print_dot_node(node->right);
}
// Výpis stromu vo formáte Graphviz
// obrázok stromu vytvoríte:
// program | dot -T png -o obrazok.png
void print_dot(struct tree* node){
printf("digraph G {\n");
print_dot_node(node);
printf("}\n");
}2. Vytvorte funkcie pre spočítanie listových a nelistových uzlov
Spočítať uzly v strome môžme rekurzívne alebo iteratívne.
Ak sa rozhodneme pre iteratívny spôsob, vytvoríme si pomocný smerník na aktuálny uzol a ten potom posuňme ďalej podľa zvolených pravidiel prechádzania.
Ak je si zvolíme spôsob inorder, potom ak existuje, navštívime najprv ľavého syna. Potom vyhodnotíme hodnotu a nakoniec, ak existuje, navštívime pravého syna:
// TODO - vyskúšať
int counter = 0;
int si = 0;
struct tree* stack[SIZE];
struct tree* this = tree;
while (si >= 0){
assert(si < SIZE);
if (this->left){
stack[si++] = this;
this = this->left;
continue;
}
counter += 1;
if (this->right){
stack[si++] = this;
this = this->right;
continue;
}
si = si -1;
}3. Spustenie znalostného systému
Keď budete mať znalostný systém v pamäti, môžete ho vyskúšať. Beh znalostného systému je rovnaký ako preorder prechádzanie binárneho vyhľadávacieho stromu.
Najprv zobrazte otázku alebo odpoveď, ktorá je uložená ako hodnota uzla. V prípade, že uzol nemá potomkov, skončite program. V prípade, že uzol má potomkov, zobrazte výzvu na zadanie odpovede áno alebo nie. Ak bola odpoveď áno, rekurzívne pokračujete ľavým potomkov, v prípade, že odpoveď bola nie pokračujte pravým potomkov. Ak odpoveď bola niečo iné , zobrazte chybové hlásenie a ukončite program.